
Génèse : deux pistes de recherche
L’intelligence artificielle (IA) est un terme mouvant, généralement employé pour désigner un programme informatique, un ensemble d’algorithmes capable de prendre des décisions relevant ou semblant relever d’une certaine forme d’intelligence. De tels programmes sont appelés modèles en IA.
Historiquement, ces programmes d’intelligence artificielle se divisent en deux grands types.
- L’IA symbolique qui se base sur la logique et des règles définies, fournies par le programmeur.
- L’apprentissage machine (machine learning), qui va apprendre de ses essais et erreurs sans règles prédéfinies.
Le premier ne peut s’appliquer qu’à des situations pour lesquelles il a été explicitement programmé.
Dans le cas de l’apprentissage machine, la recherche s’inspire de la biologie. Le cerveau humain compte environ 85 milliards de neurones connectés entre eux par 100 000 milliards de synapses. L’apprentissage y procède de la modification de l’efficacité des synapses, c’est-à-dire la capacité à transmettre un signal en fonction des signaux entrants. C’est cette efficacité que les algorithmes d’apprentissage vont singer en utilisant des poids numériques pour modifier la transmission des signaux des neurones artificiels entre eux, poids que la phase d’apprentissage va permettre de fixer.
Tel est l’un des plus grands mystères de l’intelligence : des comportements intelligents émergent d’un réseau d’unités toutes simples en interaction, par modification des connexions entre elles. (Yann Le Cun, responsable de l’IA chez Meta, Quand la machine apprend, Jacob, 16 octobre 2019)
C’est là une différence majeure avec les IA symboliques qui prévalaient jusqu’alors. Dans les IA connexionnistes (à base de neurones artificiels), la taille du modèle ne varie pas : une fois le nombre de neurones artificiels déterminés, celle-ci reste constante et ne grossit pas avec l’apprentissage. Seules les valeurs des poids sont modifiées. Exactement comme le cerveau humain qui ne pèse pas plus lourd le soir que le matin même si des choses ont été apprises dans la journée. Pour les IA symboliques, en revanche, les nouvelles données sont soit ajoutées au programme, soit transcrites en règles, ce qui alourdit d’autant la taille totale du programme.
Les deux approches sont assez vieilles et ont longtemps été en concurrence. Dès 1957, le perceptron inventé par Franck Rosenblatt simulait des neurones biologiques par algorithme. Mais les recherches, qu’elles soient menées par les symbolistes ou les connexionnistes, connaissent des difficultés de financement à l’orée des années 1970, c’est ce qu’on a nommé le premier hiver de l’intelligence artificielle. Le manque de puissance de calcul des ordinateurs d’alors empêchait leur utilisation pour des problèmes industriels.
Dans les années 1980, les systèmes experts, des algorithmes symboliques dont les règles sont fournies par des experts humains du domaine d’application permettent son utilisation dans les entreprises et connaissent alors un regain d’intérêt. Parallèlement, le connexionnisme jouit lui aussi de ces investissements et les premiers réseaux de neurones artificiels (simulés par ordinateur) voient le jour. Ils sont fonctionnels mais moins performants que les modèles experts. Mais là encore, le développement technologique fait défaut et la puissance de calcul disponible ne permet pas de répondre à l’attente des industriels, les financements se tarissent, c’est le second hiver de l’IA.
Le sujet suscite un nouveau regain d’intérêt dans les années 1990, l’amélioration des processeurs remet l’IA à l’ordre du jour et des paliers qualitatifs sont franchis. En 1997, Deep Blue de IBM, basé sur l’IA symbolique, bat le champion du monde d’échecs Garry Kasparov. Malgré cela, l’approche symbolique se frotte à ses limites, l’implémentation des règles est couteuse et fastidieuse et le besoin d’exhaustivité de ces règles rend ses applications très restreintes.
Ce n’est que 15 ans plus tard que l’approche connexionniste va réellement pouvoir être déployée et va supplanter l’IA symbolique. Il aura fallu pour cela le passage en qualité non pas d’une mais de deux quantités.
- La puissance de calcul augmente fortement dans les années 2010 principalement grâce aux processeurs graphiques initialement produits pour le jeu vidéo et la modélisation 3D et aujourd’hui largement utilisée pour l’IA et le minage de cryptomonnaie.
- La quantité de données, puisque les algorithmes d’apprentissage ne donnent des résultats pertinents que sur des gros volumes de données. L’informatisation de la seconde moitié du 20e siècle et surtout l’explosion d’internet à compter de la fin des années 1990 permettent de rassembler des montagnes de données, textuelles, visuelles, sonores, vidéo…
Ces deux éléments permettent à l’apprentissage machine de donner toute sa pleine mesure. En 2012, le concours annuel de reconnaissance automatique d’image, ImageNet, est remporté pour la première fois par un réseau de neurones artificiels, celui Geoffrey Hinton (prix Nobel de physique 2024) et ses étudiants. L’année suivante, la plupart des participants optent pour les IA connexionnistes. En 2017, 20 ans après DeepBlue, AlphaGo l’IA basée sur un réseau de neurones de Google Deepmind bat le champion du monde de jeu de go.
Le fonctionnement d’un modèle d’IA
Un réseau de neurones prend des données en entrée. Celles-ci doivent être transformées en une représentation numérique et découpée en jetons (en anglais token, un paquet de nombres). Le choix de la méthode de transformation est important pour la pertinence du réseau. Dans le cas d’un texte, attribuer un jeton à chaque mot permettra au modèle d’établir plus facilement des relations entre ceux-ci, de la même manière, dans le cas d’une image choisir des jetons représentant une surface de l’image plutôt qu’un unique pixel facilitera la reconnaissance de motifs.
Les jetons constituent les signaux présentés en entrée du modèle. Ces signaux arrivant sur une couche de neurones sont pondérés (le poids de chacun des neurones fait partie des paramètres du modèle) et additionné d’un biais (l’ensemble de ces biais fait aussi partie des paramètres) puis une fonction (mathématique) d’activation détermine les sorties de chaque neurone qui seront transmises aux neurones de la couche suivante. Il y a autant d’itération de ce processus que le modèle contient de couches de neurones.
La couche de sortie donne le résultat.
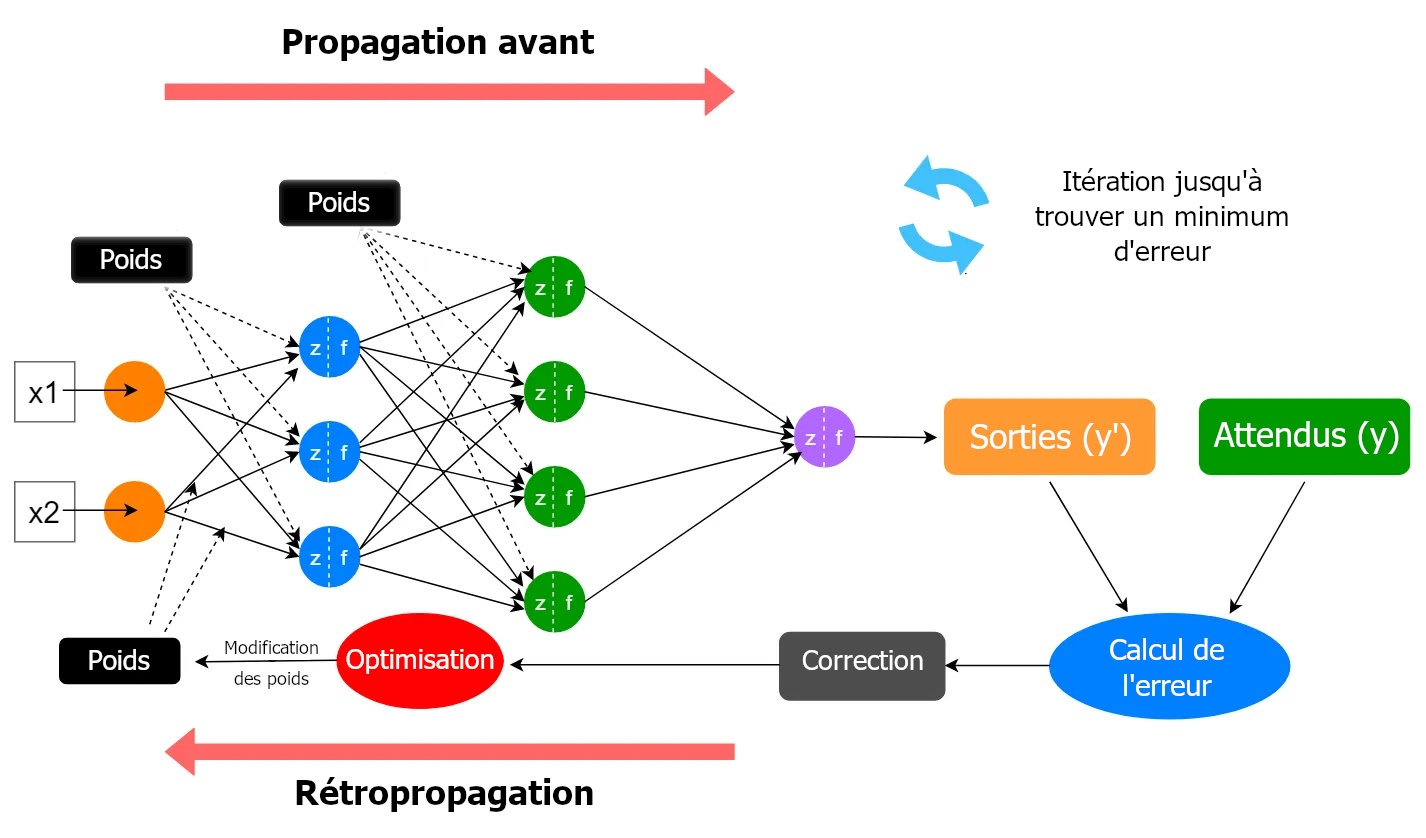
Lorsque l’on parle de modèle d’IA, on englobe toute l’architecture, le nombre de couches de neurones, le nombre de neurones par couche, les connexions entre les neurones, la méthode de modification des poids pour améliorer les résultats (rétropropagation) et la manière de présenter les données en entrée.
Pour entrainer ces modèles d’IA, il existe plusieurs types d’apprentissage, le plus répandu est l’apprentissage supervisé. Lors de la phase d’entrainement, un ensemble de données est présenté au modèle avec pour chacune d’elles le résultat attendu. Ce peut être avec des données étiquetées préalablement par l’humain ou des données dont le résultat est calculé statistiquement à partir d’une base de données.
En cas d’écart entre la sortie attendue pour ces données en entrée et la sortie obtenue, on calcule l’importance de cet écart qui va permettre de déterminer l’importance des corrections à apporter aux paramètres, la rétropropagation va permettre de modifier ceux-ci en fonction de leurs contributions au résultat.
Pour éviter qu’une correction effectuée suite à une erreur n’écrase le réglage des paramètres ayant permis de bons résultats préalables, cette rétropropagation de l’erreur ne se fait pas sur chaque cas de données d’entrée mais sur un ensemble complet de données (dit mini-batch).
En résumé, 5 étapes sont nécessaires à l’entrainement du modèle :
- La numérisation des données d’entrée (images, textes, etc.) et leur découpage en signaux.
- Le traitement des signaux par des couches de neurones, avec des pondérations (poids) et des biais, suivis de l’application d’une fonction d’activation.
- La propagation de ces signaux couche par couche jusqu’à la couche de sortie.
- La comparaison entre la sortie obtenue et la sortie attendue, puis la mesure de l’erreur éventuelle.
- L’utilisation de la rétropropagation pour ajuster les paramètres en fonction de leur contribution à l’erreur.
Ce type d’apprentissage nécessite des données étiquetées et donc un travail humain préalable. Les données des services de santé permettent par exemple d’obtenir un ensemble de radiographies de poumon associées à la présence ou l’absence de tumeur cancéreuse, cette association étant le fruit du suivi des patients et donc du travail humain d’équipes médicales. D’autres données peuvent provenir de sources non professionnelles comme les données publiques sur le web dont l’étiquetage dépendra du travail des internautes.
À travers cet entrainement, le modèle apprend à reconnaitre (et exploiter) des motifs ou des schémas présents dans les données. Il détecte des régularités et des structures répétitives qui lui permettent ensuite de généraliser et de faire des prédictions sur de nouvelles données. Aussi à l’issue de son entrainement, lorsque de nouvelles données sont présentées au modèle, il sera en mesure d’y appliquer le fruit de son entrainement. C’est ce que l’on nomme la phase d’inférence.
Ces modèles ne suivent donc pas des règles de logique prédéfinies par l’humain mais apprennent par leur fonctionnement interne à extraire les caractéristiques des données pour fournir le bon résultat. Étant donné le nombre gigantesque de paramètres en jeu (plusieurs centaines de milliards), il devient impossible à un être humain de suivre et donc de comprendre le cheminement qui mène au résultat final. On parle souvent de « boite noire ». De plus, lors de la phase d’inférence, le modèle démontre une capacité à généraliser le fruit de son apprentissage. Certains chercheurs voient même poindre des comportements émergents inédits, comme ce fut le cas du programme AlphaGo qui appliqua des stratégies inédites dans ses parties de go.
Le problème des hallucinations des IA
Ces intelligences artificielles se contentent d’appliquer un ensemble de transformations mathématiques à un flux de données numériques fourni ; il n’y a pas de « compréhension » de ces données ou de la finalité des taches qui leur sont confiées. D’ailleurs, une des caractéristiques des IA de « deep learning » le risque de générer des sorties qui ne font pas sens. Ce qu’on appelle des « hallucinations », est indissociable des IA actuelles. Les modèles de langage par exemple peuvent aléatoirement répondre soit de manière incohérente avec le contexte, soit de manière complètement fausse ou inventée. Toutes les technologies utilisant ces IA sont impactées, de la génération d’images à l’aide à la conduite. Ce qui limite pour le moment l’autonomie de tels outils.
Un juge fédéral du Texas, Brantley Starr, a ordonné que tout contenu généré par une intelligence artificielle (IA) soit déclaré et vérifié par un être humain avant d’être utilisé dans un dépôt judiciaire. Cette décision fait suite à un incident où un avocat, Steven Schwartz, a laissé ChatGPT, un modèle de langage basé sur l’IA, lui fournir des cas et des précédents juridiques inventés de toutes pièces. (Developpez.com, 1er juin 2023)
Ces hallucinations rendent les outils d’IA impropres à toute fonction critique ou des problèmes de cybersécurité. Cela est d’autant plus problématique pour les capitalistes du domaine que les modèles plus performants semblent également halluciner davantage.
Les dernières technologies, plus puissantes -les systèmes dits de raisonnement tels ceux d’OpenAI, de Google et de la jeune pousse chinoise DeepSeek- génèrent davantage d’erreurs, et non pas moins. Alors que leurs compétences en mathématiques se sont considérablement améliorées, leur maitrise des faits s’est affaiblie. (New York Times, 6 mai 2025)
Selon une étude d’OpenAI, son modèle de langage o3 a un taux d’hallucinations supérieur de 15 à 100 points par rapport à o1, un modèle plus ancien. Cette hausse est même comprise entre 80 et 200 points pour le modèle o4-mini.
L’emballement des spéculateurs
Nombre d’études sur les gains de rentabilité induits par l’utilisation de l’IA générative promettent un gain gigantesque ; d’autres se montrent plus sceptiques. La Commission de l’intelligence artificielle table, le 13 mars 2024 sur une hausse de la croissance française de 1,35 % par an. Goldman Sachs prévoit une hausse du PIB mondial de 7 % sur 10 ans, et une augmentation de la croissance de 1,5 point par an sur la même période. Le FMI prévoit même une hausse du PIB mondial pouvant atteindre 16 %. Mais certains comme le prix Nobel d’économie Daron Acemoglu s’avèrent plus que réservé. Ce dernier prédit une hausse de productivité globale des facteurs entre 0,53 % et 0,66 % en 10 ans. Une prudence en partie partagée par la Direction générale du Trésor.
La DGT reconnait certes que certaines études suggèrent des effets positifs significatifs sur la productivité des travailleurs, mais elle retient surtout que les gains de productivité sont encore peu observables au niveau macroéconomique du fait d’une adoption encore limitée de l’IA par les entreprises et les salariés. (Rapport sénatorial, 28 novembre 2024)
De leur côté, les entreprises consommatrices même sans savoir comment inclure l’IA dans leurs chaines de production s’en emparent pour ne pas être distancé par les concurrents.
Elles ont tellement peur d’être exclues d’une révolution en cours qu’elles achètent une sorte d’outil d’IA et essaient de comprendre comment l’utiliser pour créer de la valeur. (Jim Siders, DSI de Palantir, 11 février 2025)
Le prix de ces technologies est également un frein à leur adoption.
La question du cout, en effet, est loin d’être anodine, qui plus est à une période où les marges de manœuvre financières des entreprises se réduisent. Parmi celles qui ont adopté la technologie, la question du retour sur investissement n’est pas totalement tranchée. (Le Monde, 7 février 2025)
Une étude menée par IBM au printemps 2025, estimait à 25 % la part des projets d’IA en entreprise ayant atteint un retour sur investissement.
Ces incertitudes devraient pousser les capitalistes à la prudence mais dans un contexte d’économie mondiale en berne, ceux-ci se précipitent sur ce que certains présentent comme la poule aux œufs d’or. Depuis l’ouverture au grand public de ChatGPT, le modèle de langage d’OpenAI en novembre 2022, les performances des actions des sept magnifiques (magnificent seven : Alphabet, Amazon, Apple, Meta, Microsoft, Nvidia et Tesla) ont explosé, portées par l’envolée du prix de leurs actions. Actuellement ces sept entreprises représentent 35 % de la capitalisation boursière du S&P500 (indice boursier des 500 plus grosses entreprises cotées sur les bourses des États-Unis, NYSE ou NASDAQ). Nvidia, premier concepteur de cartes graphiques est devenu en juin 2024 la première capitalisation boursière mondiale.
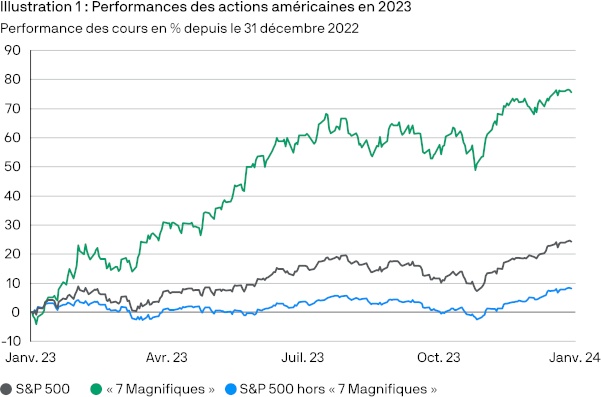
Toutefois, cet emballement est le fruit d’un pari de rentabilité future comme le montre l’écart entre le ratio P/E (rapport entre le dernier cours de clôture et le dernier bénéfice par action) des sept magnifiques et celui des entreprises du S&P500. Ce qui n’est pas sans rappeler la « bulle internet » de la fin des années 1990.
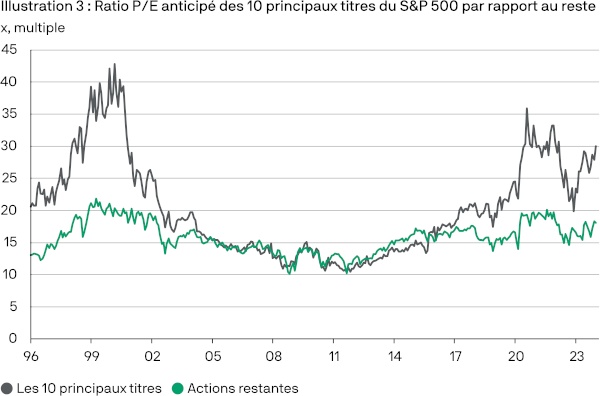
Bien que la vitesse de déploiement et d’adoption de l’IA soit impressionnante, il est difficile, à ce stade, d’évaluer avec certitude son impact. Nous sommes conscients que d’anciens « miracles technologiques », tels que l’Internet, n’ont souvent pas eu l’impact escompté sur la productivité et les bénéfices, que ce soit au niveau micro ou macroéconomique. […] Dans ce cas, nous pourrions assister à un résultat rappelant davantage la bulle technologique : la performance des plus grandes entreprises pourrait « rattraper » celles d’autres actions dont les prévisions de bénéfice sont plus prosaïques. (J.P. Morgan Asset Management, 8 février 2024)
Un premier emballement des investissements avait eu lieu en 2020 consécutivement à la crise sanitaire et aux confinements qui avaient entrainé une hausse de la consommation des outils numériques à la fois dans la sphère professionnelle pour la mise en place du télétravail à grande échelle et dans la sphère privée avec l’augmentation de la consommation de contenu numérique (audios, vidéos, jeux vidéo). Cet afflux massif d’investissement avait entrainé un « rééquilibrage » à partir de 2022 avec des centaines de milliers d’emplois supprimés par les géants de la Tech américaine (460 000 sur les années 2022-2023 dont 67 % pour les seules sociétés américaines). La nouvelle bulle se développant depuis la fin de 2022 est portée, elle, par la percée des IA générative.
Dans le domaine des technologies informatiques, de nombreuses crises ont déjà eu lieu, sélectionnant les diverses innovations. La « bulle internet » de la fin du 20e siècle a épargné un ensemble de technologies encore utilisé aujourd’hui ainsi que de nombreux travailleurs formés à ces technologies. La bulle des NFT plus récente, la même qui menace les cryptomonnaies, n’a, elle, rien laissé. La question est de savoir dans quelle catégorie se classera la bulle IA. Les performances de l’IA dans de nombreux domaines tendent à démontrer que cet éclatement ne marquera pas l’arrêt total de son déploiement mais une réorientation vers certains secteurs.
En définitive, c’est bien la rentabilité de l’IA qui va trancher.
- Pour ce qui est des entreprises fournisseuses d’IA, est-ce que les rentrées d’argent vont être suffisantes pour couvrir les frais d’entrainement, d’infrastructure d’électricité et de maintenance ?
- Pour les entreprises consommatrices d’IA, est-ce que les gains de productivité seront suffisants pour couvrir les investissements ?
Les hallucinations sont une donnée importante de cette équation, car en toute logique elle devrait obliger à laisser l’IA sous un contrôle humain mais en cela elle amoindrirait la rentabilité attendue par les entreprises y ayant recours. Celles-ci seraient donc tentées soit de ne pas utiliser l’IA et donc de contredire les prévisions des économistes enthousiastes et des investisseurs, soit de l’utiliser sans supervision humaine et donc risquer d’être contreproductif ou tout au moins de diminuer la qualité du produit ou du service. L’exemple bien connu est celui de la détection de tumeurs sur des radios. Le taux de réussite de l’IA est supérieur à celui des radiologues. Mais les hallucinations, même rares, obligent le radiologue à contrôler lui aussi la radio. En cas de désaccord avec l’IA, ce contrôle peut même se révéler plus long qu’avant cette technologie. La qualité des diagnostics est améliorée mais le cout total n’est pas réduit.
Aujourd’hui, vous ne pouvez pas déployer ces intelligences à moins qu’il n’y ait quelqu’un qui en assume la responsabilité en tant qu’humain (Satya Nadella, PDG de Microsoft, Dwarkesh Podcast, 19 février 2025)
Malgré le risque technique et financier, la tendance est à l’accroissement des investissements en matière d’IA.
De leur côté, les fournisseurs d’IA augmentent leur capacité. En 2023, Alphabet, Amazon, Meta et Microsoft avaient investi 145 milliards d’euros, contre 237 en 2024. Pour 2025 Amazon a déjà annoncé investir 96 milliards supplémentaires, Alphabet 72, Microsoft 77 et Meta une soixantaine de milliards pour un peu plus de 300 milliards ensemble. Et ce malgré la difficile rentabilité de ces investissements, OpenAi par exemple espère être rentable d’ici 2029 et table sur encore 200 milliards d’investissements d’ici la fin de la décennie. En attendant le créateur de ChatGPT affiche pour 2024 une perte de 1,3 milliard de dollars malgré un chiffre d’affaires de 3,7 milliards. Et ces pertes sont pour le moment limitées du fait de l’accord avec Microsoft qui lui permet d’utiliser une puissance de calcul pour un quart de sa valeur de marché.
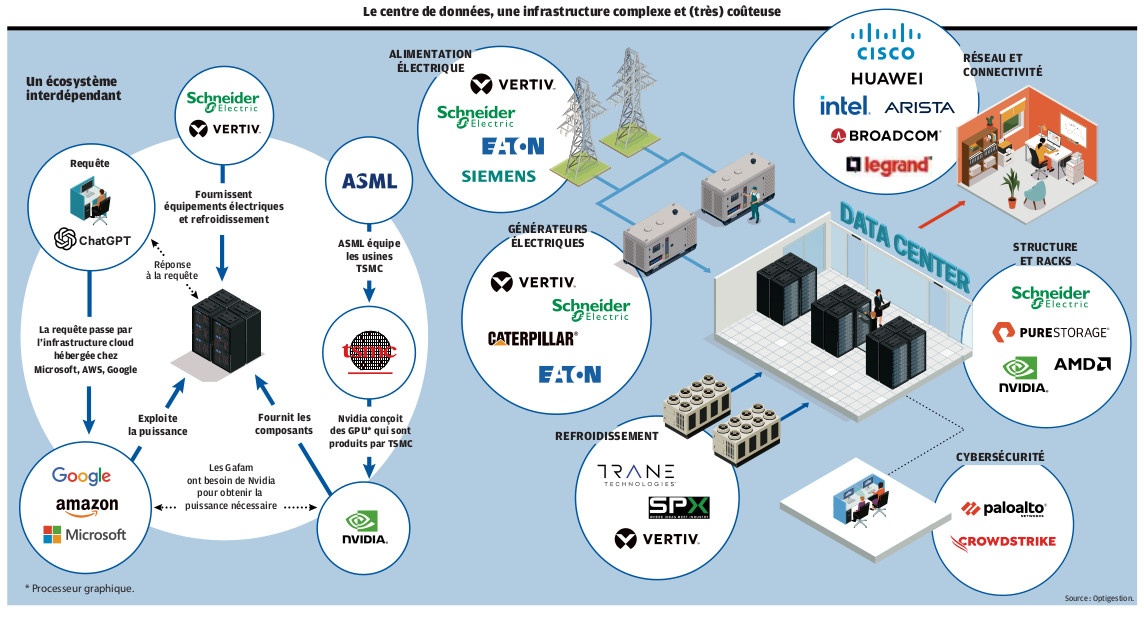
Et encore, il ne s’agit là que des acteurs technologiques en première ligne mais l’emballement embrasse également les seconds couteaux, comme les constructeurs de centre de données, les fournisseurs d’électricité, les fabricants de processeurs, les pourvoyeurs de matières premières… Le nombre d’entreprises ayant misé gros ou exclusivement sur le développement de l’intelligence artificielle est d’autant plus important que les capitaux peinent à trouver des débouchés ailleurs. C’est donc tout un pan de l’économie mondial qui parie sur d’hypothétiques profits, rien d’étonnant à ce que la moindre secousse fasse paniquer tout ce petit monde.
Le 27 janvier la startup chinoise DeepSeek publie son propre modèle de langage R1, aux performances équivalentes à ce que proposent les mastodontes américains et leurs concurrents occidentaux. L’entreprise chinoise précise que le modèle n’a coûté que 5,6 millions de dollars. Même si le montant est très certainement minimisé (une enquête l’estime à 1,6 milliard de dollars), l’écart entre les moyens déployés et ceux mis en branle par les géants californiens est colossal (au même moment OpenAI levait 40 milliards de dollars de SoftBank venant s’ajouter aux dizaines de milliards déjà investis par diverses sociétés).
Nous ne connaissons pas le cout exact, et il y a de nombreuses réserves à formuler sur les chiffres que DeepSeek a publiés jusqu’à présent. Il est presque certain que le montant est supérieur à 5,6 millions de dollars […] Mais même s’il coute 10 fois plus cher que ce que prétend DeepSeek, et même si on prend en compte d’autres couts qui ont peut-être été exclus, comme les salaires des ingénieurs ou les couts de recherche fondamentale, ce serait toujours des ordres de grandeur inférieurs à ce que les entreprises américaines d’IA dépensent pour développer leurs modèles les plus performants. (New-York Times, 28 janvier 2025)
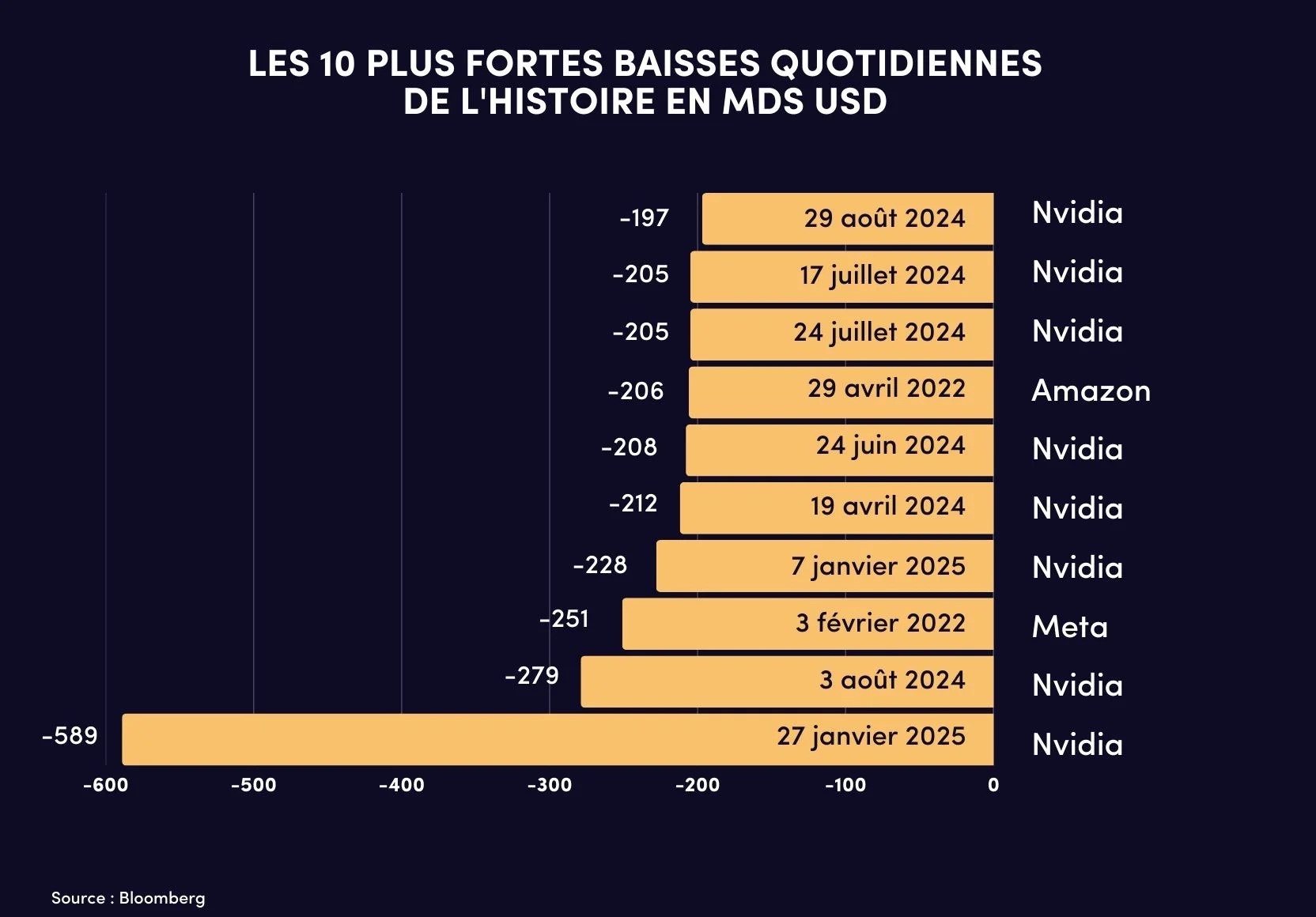
La réaction boursière est immédiate, jusqu’à 1 000 milliards de dollars de capitalisation mondiale s’envole dans la journée. Nvidia est la plus touchée mais toutes les entreprises de la Tech américaine sont impactées emportant avec elles leurs actuels et futurs fournisseurs, des data centers jusqu’au startup du secteur de l’énergie nucléaire. Mais cet accrochage appelé par certains journalistes le « moment Spoutnik » de l’IA ne s’est pas traduit par un effondrement du secteur.
La bulle pourrait aussi éclater par un autre biais, actuellement le paradigme retenu par les entreprises d’IA est que celle-ci nécessite les derniers modèles de processeurs graphiques pour progresser, or ce que montre le cas DeepSeek c’est que ce paradigme n’est pas absolu. En ce cas, l’attrait pour les investissements dans les concepteurs de cartes graphiques tel que Nvidia pourrait alors s’inverser et entrainer l’effondrement de tout l’écosystème par la chute de son champion. Symbole de cette contradiction entre euphorie et incertitude, Nvidia détient 8 des 10 plus fortes chutes boursières de l’histoire sur une journée.
Dans tous les cas, la situation commence à préoccuper certains acteurs.
Je commence à voir le début d’une sorte de bulle. Je commence à m’inquiéter lorsque les gens construisent des centres de données sur mesure. Il y a un certain nombre de personnes qui se présentent, des fonds qui sortent, pour lever des milliards ou des millions de capitaux (Joe Tsai, PDG d’Alibaba, South China Morning Post, 25 mars 2025)
Aux mains d’une poignée de puissances impérialistes
Loin des mythes libéraux, c’est open bar pour les capitalistes de l’IA assoiffés d’argent public. Du moins quand leur État est bien placé dans la chaine impérialiste mondiale.
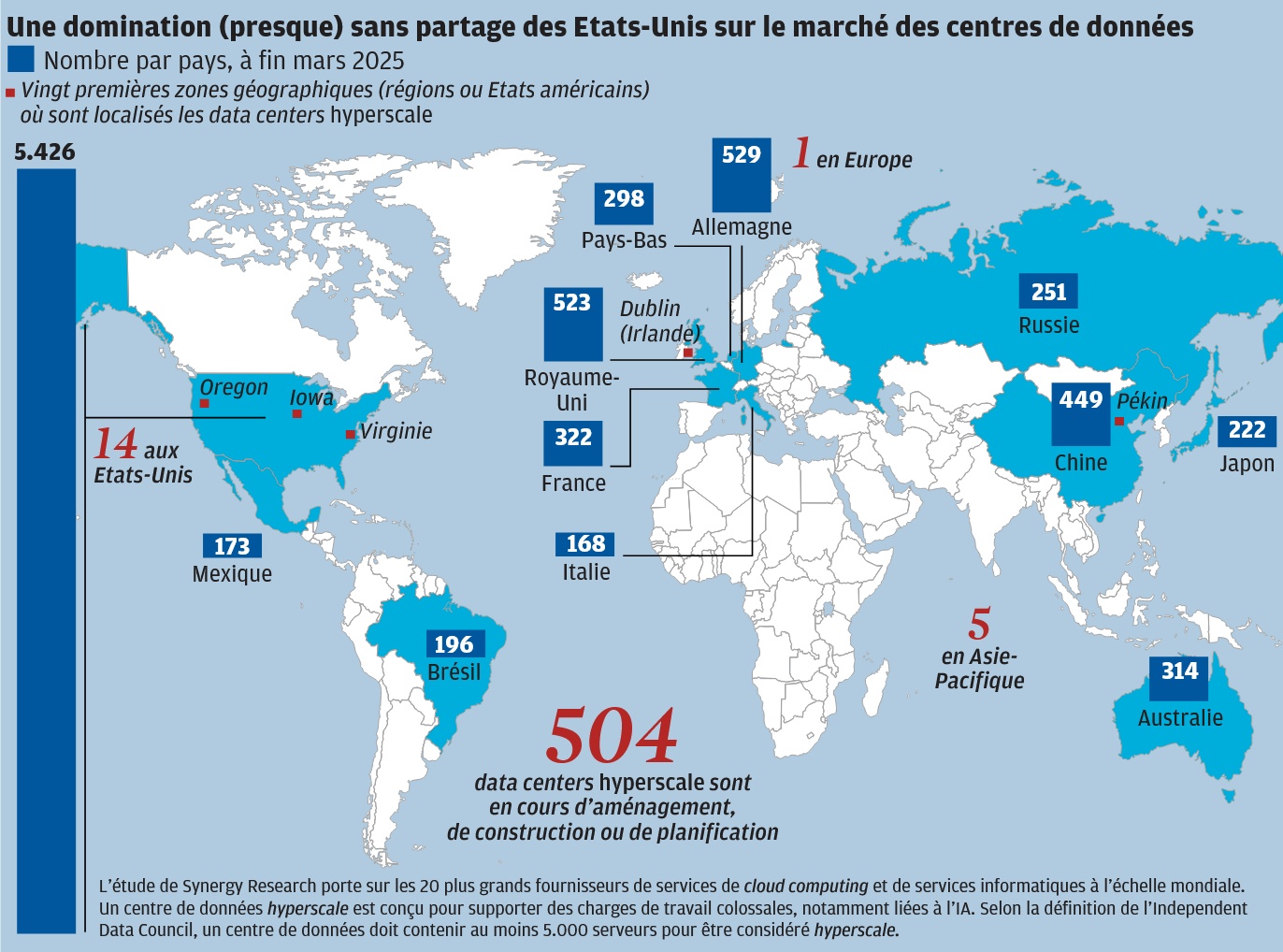
Les États-Unis essaient de garder la Chine à distance, mais ne comptent pas non plus laisser une place aux impérialismes européens. Lors du sommet de Paris sur l’IA le 11 février, le vice-président américain résumait « les États-Unis sont les leaders de l’IA et entendent le rester ».
Le 21 janvier, Trump annonce Stargate, un plan de 500 milliards de dollars piloté par Oracle, OpenAi, SoftBank et le fonds émirati MGX. L’Union européenne fait de même, à son échelle, le 11 février, avec InvestAI, un programme à 200 milliards dont 150 de fonds privés. En France, Macron convoque les 10 et 11 février un sommet sur l’IA lors duquel il a annoncé 109 milliards d’euros d’investissements privés en France dans ce domaine. Emmenés par les Émirats arabes unis (30 à 50 milliards d’euros), là aussi via MGX, le fonds canadien Brookfield (20 milliards d’euros), le fonds BlackRock et Microsoft (30 milliards), le britannique Fluidstack (10 milliards), Amazon (6 milliards), BPI France (10 milliards), Illiad de Xavier Niel (3 milliards), Orange, Thales, la startup française Mistral AI, ainsi que d’autres sociétés et fonds d’investissements américains, japonais et suédois complètent le tableau.
L’impérialisme chinois ne souhaite pas voir son rival prendre le large en ce qui concerne l’IA, le 23 janvier, soit deux jours après l’annonce du plan américain Stargate, Bank of China dévoile un plan de 138 milliards sur 5 ans. Fin février, Alibaba (propriétaire d’AliExpress et concurrent d’Amazon) annonce investir 52 milliards de dollars sur 3 ans dans l’IA, ByteDance (propriétaire de TikTok et concurrent de Meta/Instagram) devrait dépenser cette année 22 milliards. Mais c’est tout le secteur chinois qui investit dans l’IA, Baidu (concurrent de Alphabet/Google), Tencent (Géant du jeu vidéo et de la messagerie instantanée, concurrent de Meta/Whatsapp), Huawei (fabricant de smartphone, de semi-conducteurs et de puces concurrent de Nvidia et Apple), ainsi que beaucoup de startup dont la plus connue est DeepSeek.
Les restrictions d’exportation de puces américaines vers certaines entreprises chinoises, mais aussi européennes, décrétées par Trump lors de son premier mandat, déjà amplifiées par son successeur, ont récemment été renforcées.
L’administration de Joe Biden a déjà instauré des contrôles sur les modèles d’IA les plus puissants et étendu les limitations de ventes à la Chine des puces utilisées pour l’IA, en instaurant des quotas pour 120 pays, dont certains de l’Union européenne, ce qui suscite des craintes dans les startups. (Le Monde, 9 février 2025)
La liste des équipements interdits ainsi que celle des entreprises visées a été élargie. En réponse le gouvernement chinois, qui avait lui aussi déjà restreint ses exportations de terres rares à destination des États-Unis, a bloqué totalement le 14 avril ces exportations dans le cadre de la guerre douanière à laquelle se livrent les deux grandes puissances impérialistes. Les sanctions de 2019 contre Huawei tout comme l’interdiction ou le rachat annoncé de TikTok découlent de la même logique, à la fois porter un coup à un concurrent direct et rester maitre de la captation massive de données dans le monde.
L’Inde contribue jusqu’à présent à l’IA par l’émigration de sa main-d’œuvre très qualifiée aux Etats-Unis et, sur place, par des « annotateurs de données » parlant anglais (évalués entre 70 000 et 200 000 personnes) mais l’État bourgeois tente de doter son capitalisme d’entreprises proprement nationales.
Le pays a lancé en mars 204 une mission pour l’intelligence artificielle, l’IndiaIAIMission. Cette dernière est dotée d’un budget de 1,2 milliard de dollars. L’objectif est de développer des modèles d’IA dans le domaine de l’agriculture, de la ville durable, de la santé… (Le Monde, 7 mai 2025)
De leur côté, les bourgeoisies européennes tentent de freiner les géants américains par l’intermédiaire du règlement général de l’UE sur la protection des données (RGPD), la législation la plus stricte au monde en matière de protection de la vie privée et de sécurité. Il a été adopté en 2016 et est entré en application le 25 mai 2018. Sur ses 5 premières années d’application, le RGPD a donné lieu à un total de 4 milliards d’euros d’amende dont plus de 3 milliards pour les seuls Meta et Amazon. Dans le cadre de la guerre commerciale déclenchée par Trump, des sanctions de l’UE contre les GAFAM sont opportunément à l’étude. L’UE tente de s’adapter à la généralisation de l’IA.
Elle a beau hérisser l’administration Trump, la législation européenne applicable à la tech poursuit, pour le moment, sa mise en route. Il en va ainsi du règlement sur l’intelligence artificielle, dont certaines dispositions centrales entrent en vigueur le 2 aout, un peu plus d’un an après l’adoption de ce texte, un des plus ambitieux au monde dans ce domaine. (Le Monde, 3 aout 2025)
Mais la dépendance technologique européenne envers les États-Unis en fait un rival bien anémique, laissant au seul impérialisme chinois le rôle de véritable concurrent sur ce marché. De plus, la Chine, comme dans une moindre mesure la Russie, a empêché que son réseau internet ne soit accaparé par les ogres américains et possède ses propres géants du web, ce qui lui assure un accès à des données massives.
Les replis protectionnistes et la guerre commerciale ouverte engagée par l’impérialisme dominant n’épargneront évidemment pas le domaine de l’intelligence artificielle.
Les échanges ont en effet démontré que l’heure est moins à la négociation sur l’encadrement de l’IA qu’à la course entre puissances. (Le Monde, 9 février 2025)
Une quête de rentabilité vitale
Actuellement, OpenAI facture 20 dollars par mois et par personne pour les particuliers et les petites entreprises et 60 dollars par personne pour les entreprises de plus de 150 salariés. D’autres fournisseurs font payer uniquement les entreprises en fonction de leurs chiffres d’affaires, comme Stability AI (créateur du générateur d’image Stable Diffusion) qui ne facture que les entreprises réalisant au minimum 1 million de dollars de chiffre d’affaires, c’est le modèle que pourrait suivre Meta. Toutes ces entreprises ont un service gratuit et limité pour les particuliers servant de vitrine promotionnelle.
Mais, pour devenir rentables, les entreprises d’IA doivent réduire leurs couts, augmenter leurs prix ou développer des capacités internes telles que les puces et les centres de données afin de réduire leur dépendance à l’égard des autres entreprises.
Le quasi-monopole de Nvidia sur les puces utilisées en IA, pousse en effet les entreprises du secteur à essayer de court-circuiter cet acteur. En aout dernier, Microsoft lançait les hostilités avec Maia 100, sa puce dédiée à l’IA, en novembre, Amazon dévoilait la deuxième version de sa puce Trainium, le mois suivant, Google annonçait Trillium, en février c’est OpenAI qui présentait sa puce maison pour laquelle elle s’allie au géant taïwanais des semi-conducteurs TSMC un choix qu’a également fait Méta. Les entreprises chinoises cherchent elles aussi à développer leurs propres puces, cela leur est d’autant plus impératif que les restrictions d’export de celles-ci prononcées par les États-Unis risquent de les reléguer de la compétition internationale. Ainsi, le 21 avril, Huawei annonce la mise en production de son processeur graphique 910C, dont les premières livraisons sont attendues pour le mois suivant.
Passé l’actuelle euphorie boursière, la concurrence à laquelle se livrent ces entreprises aboutira à un amoindrissement de leur nombre, les petits seront avalés par les plus gros comme dans chaque secteur capitaliste. Les capitalistes se positionnent déjà, Amazon a investi 8 milliards de dollars dans Anthropic, Microsoft 13 milliards dans OpenAi. Musk, le patron de X/Twitter propriétaire du modèle de langage Grok, après avoir essayé d’acheter OpenAi pour 97 milliards de dollars a tenté de faire empêcher par la justice sa transformation en société à but lucratif. Méta s’est également opposé à cette conversion. De son côté, Microsoft tout en gardant un pied dans OpenAI couvre ses arrières en développant des solutions d’IA en interne. Tout comme Alphabet/Google qui bien qu’étant lui-même fournisseur d’IA (notamment via son modèle Gemini) a investi des milliards dans Anthropic.
Autre cout important, la qualification (l’étiquetage) des données indispensables dans les modèles à apprentissage supervisé et qui nécessite du travail humain qui, bien que faiblement rémunéré, augmente les couts proportionnellement à la taille du jeu de données d’entrainement.
Des humains sont donc essentiels pour entrainer les IA, soit pour générer des données, par exemple en se filmant passant devant une caméra, soit pour vérifier que les prédictions du modèle sont correctes. Mais l’activité principale consiste à annoter les textes ou les images, afin de construire le corpus d’apprentissage, par exemple en indiquant sur la photo d’un carrefour quels sont les panneaux de signalisation, ou en identifiant des traces de rouille sur des photos de poteaux électriques, ou en repérant si un client est en train de voler dans un magasin. (Le Monde, 22 juin 2024)
Des travailleurs sont ainsi nécessaires pour étiqueter, classer, signaler les données, de nombreuses sociétés se sont donc spécialisées dans l’exploitation de salariés à ces fins. Soit en proposant à des internautes d’effectuer ces taches de chez eux moyennant un modique paiement, soit en employant de la main-d’œuvre à peu de frais dans des pays dominés (comme la start-up française Innovatiana). L’emploi de ces « travailleurs du clic » n’est pas nouveau puisqu’ils appliquaient déjà la modération sur les réseaux sociaux au prix de souffrances psychologiques et pour un salaire de misère.
Il y a 10 ans, les micro-travailleurs se trouvaient surtout dans les pays asiatiques : Inde, Indonésie, Malaisie, Pakistan et Bangladesh. C’était une cartographie très orientée par la langue anglaise. Dernièrement, avec l’essor de l’IA dans d’autres langues, ce marché du travail a évolué. Par exemple, l’IA à la française est faite en Afrique francophone, à Madagascar, en Côte d’Ivoire et au Sénégal notamment. Les ouvriers du clic ont aussi connu un essor en Amérique du Sud, pour les marchés hispanophones. La situation économique de certains pays du continent favorise le phénomène, en particulier au Venezuela, où la crise économique qui dure depuis des années rend ce micro-travail attrayant. (National Geographic, 15 octobre 2020)
Le phénomène touche aussi les couches les plus pauvres des pays impérialistes, en France en 2020 on estimait à 260 000 le nombre de personnes inscrites sur des plateformes de micro-travail dont 50 000 actifs mensuellement.
L’intelligence artificielle comme arme
Pour le moment, les armées et les polices constituent le seul secteur qui dépense sans retenue.
Les solutions de vidéosurveillance avec reconnaissance faciale par IA se vendent sur toute la planète et notamment à Paris à la faveur des Jeux olympiques de 2024. En France, entre 2018 et 2022, sur les financements de l’État à l’IA, 410 millions sont allés directement à l’armée, 445 millions ont été alloués à la recherche (dont certains sont en fait des subventions à la recherche des entreprises privées pour le l’IA à des fins militaires). De la même manière, le plan France 2030 annoncé en octobre 2021, prévoyait une enveloppe de 2,2 milliards d’euros d’investissement dans l’IA pour l’économie du pays tandis que la loi de programmation militaire 2024-2030 adoptée en juillet 2023 consacrait 2 milliards de financements pour l’IA dans l’armée.
Le ministre des armées Lecornu a annoncé un partenariat avec Mistral AI. L’IA est utile pour la guerre, notamment pour le renseignement, le ciblage autonome, le pilotage de drone et de missile. Par exemple, la jeune pousse allemande à participation britannique et française Helsing fournit des drones de frappe dotés d’IA à l’Ukraine. Elle s’inscrit dans le militarisme européen.
Fin mai et début juin, Helsing a testé pour la première fois avec succès Centaur, son programme de pilotage autonome d’un avion de chasse, développé en six mois. Installé sur un appareil Gripen E du suédois Saab, le logiciel a pris en main le pilotage et effectué plusieurs opérations en autonomie au-dessus de la mer Baltique, avec un pilote ayant seulement servi de contrôle. (Le Monde, 9 aout 2025)
Des sociétés américaines spécialisées comme Anduril et Palantir se sont alliées à OpenAi et SpaceX pour répondre aux appels d’offres du Pentagone
À Gaza, l’armée israélienne utilise des IA pour analyser les masses de données recueillies ou pour déterminer automatiquement des cibles à atteindre, grâce aux géants américains, Google officiellement depuis le 4 février (même si le Washington Post avait dévoilé qu’il avait déjà collaboré au génocide en 2024) ou Microsoft.
Microsoft serait l’un des principaux fournisseurs de services cloud et d’IA de l’armée israélienne. L’utilisation des services de Microsoft par Israël aurait augmenté de façon spectaculaire dans les mois qui ont suivi l’attaque du Hamas 7 octobre 2023. Des documents divulgués révèlent que Microsoft a conclu des contrats d’au moins 10 millions de dollars pour fournir des milliers d’heures d’assistance technique pendant la guerre à Gaza. (Developpez.com, 5 avril 2025)
Une situation qui fait réagir des travailleurs du secteur. Des pétitions et des manifestations de salariés de Google et Amazon dénoncent à plusieurs reprises le projet Nimbus, un contrat de 1,2 milliard de dollars avec le ministère de la défense d’Israël. Les protestations des salariés n’ont que des licenciements pour réponse.
Un gouffre énergétique
L’informatique est une grande consommatrice d’énergie électrique et l’explosion de l’IA risque d’amplifier le phénomène. En 2022 la consommation des 8 800 centres de données représentait 460 TWH soit à peu près la consommation électrique française (445 TWH en 2023), environ 2 % de la consommation électrique mondiale.
L’Agence internationale de l’énergie (AIE) estime que cette consommation devrait atteindre les 945 TWH d’ici 2030, soit la consommation actuelle du Japon. L’IA contribuerait de manière importante à cette augmentation, lors des phases d’entrainement mais aussi lors des phases d’inférences.
Plusieurs études soulèvent qu’une requête soumise à un modèle de langage est bien plus consommatrice en électricité qu’une requête soumise à un moteur de recherche classique tel que Google, Baidu ou Qwant (d’un facteur multiplicatif allant d’une dizaine à une centaine selon le nombre de paramètres du modèle). Aussi, Si les 9 milliards de recherches quotidiennes faites sur Google étaient transférées à de telles IA, cela engendrerait une forte augmentation annuelle de la consommation électrique mondiale.
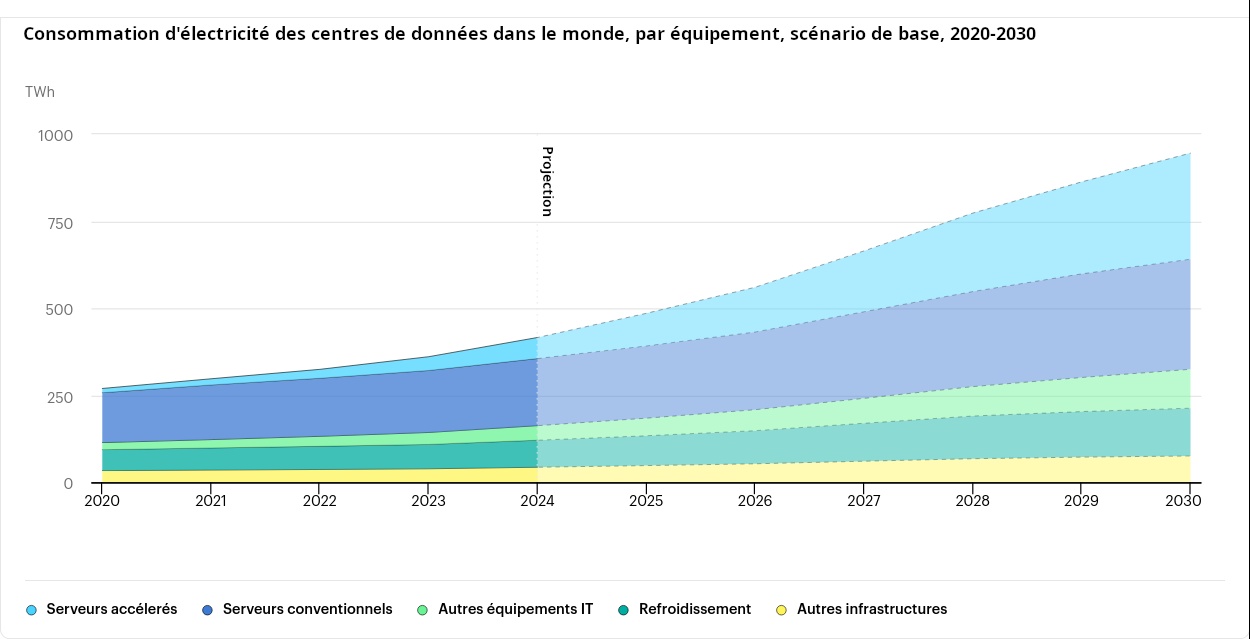
Ce besoin d’électricité pousse les géants du secteur à s’équiper, Microsoft a passé un accord avec Constellation Energy pour la relance d’un réacteur nucléaire à Three Mile Island à son profit, Google a de son côté signé avec Kairos Energy, une startup spécialisée dans la construction de petit réacteur nucléaire (SMR), Amazon a fait de même avec X-energy. Mais si ces contrats visent à la fois à s’assurer des sources d’électricité directement pilotable par les entreprises et à afficher les pattes vertes, l’électricité carbonée n’en est pas oubliée pour autant. Trump souhaite « plus que doubler » la production électrique par les centrales à charbon et a déjà exempté plusieurs dizaines d’entre-elles des contrôles sur les émissions de produits chimiques toxiques (mercure, arsenic, benzène) qui doivent entrer en vigueur en 2027.
Pillage de données publiques et de créations privées
Tous les groupes capitalistes, tout en bénéficiant de subventions, en s’emparant de la recherche publique, haïssent l’impôt et les contraintes prises, mollement, dans l’intérêt général. Désormais, pour les besoins de l’IA, ils pillent les données publiques ou gratuitement accessibles. Par exemple, les résultats concluant de l’IA dans la santé se fondent sur l’accès aux organismes publics de santé.
Une partie du financement de R&D des capitalistes de la santé est ainsi transférée à la charge de la société. En France, par exemple, le Health Data Hub lancé en 2019 permet à des sociétés privées de jouir des données de santé de la population française.
Les modèles de langages des grands groupes capitalistes américains s’entrainent sur des contenus légalement protégés par les droits d’auteur sans être pour le moment inquiétés. D’une part, parce que les corpus d’entrainement sont maintenus secrets et d’autre part parce qu’ils bénéficient du soutien de leur État. Ainsi, les maigres directives adoptées par Biden aux États-Unis ont été annulées par Trump, et le projet de régulation de la Commission européenne veut rendre obligatoire la publication de 10 % des sources d’entraînements ce qui laisse évidemment loisir au fournisseur de publier les 10 % de source qu’ils souhaitent. Malgré tout certains accords ont été signés, Open AI avec Le Monde, News Corp (Wall Street Journal, Daily Telegraph…) et Axel Springer (Die Welt, Politico…), Mistral AI avec l’AFP et Google avec Associated Press. Ces partenariats permettent à la fois de se prémunir de poursuites futures mais également d’obtenir du contenu frais. Cette complaisance des gouvernants est d’autant plus cynique qu’elle tranche avec le sort réservé au particulier qui a téléchargé illégalement un film alors que ces entreprises se passent des droits d’auteur sur des milliards de contenus.
Données ouvertes contre secrets industriels
Les IA génératives sont donc entrainées sur des données ouvertes, disponibles sur internet, mais aussi fermées telles que les livres, articles, œuvres graphiques… soumises à droit d’auteur. Toutes ces données sont par définition limitées et connaissent une croissance inférieure à l’augmentation actuelle de la taille des jeux d’entrainement de ces IA, ce qui implique un prochain goulot d’étranglement. Une étude de juin 2024 d’Epoch AI estime que la taille des données d’entrainement des modèles de langage devrait rejoindre la taille des données textuelles exploitables entre 2026 et 2032. Un risque confirmé par une étude publié par Nature le mois suivant.
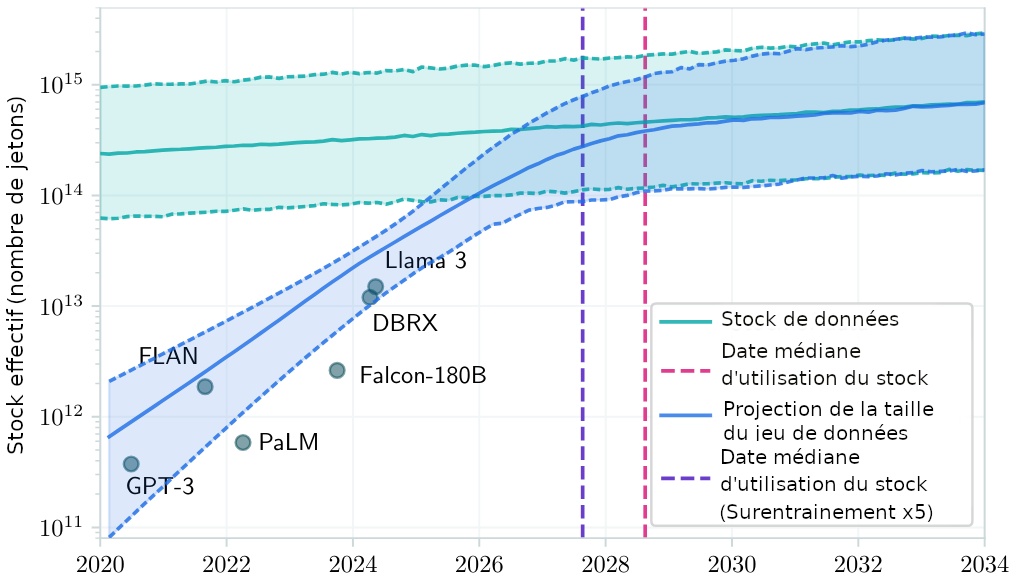
Le problème est connu des géants du secteur. Nvidia, par exemple, rachète en mars 2025 Gretel, une startup spécialisée dans la génération de données artificielles censées compenser le manque de données d’origine humaine.
Les fantasmes sur les gains de productivité ne sont pour le moment pas vérifiés, hormis dans quelques secteurs bien spécifiques, l’IA est trop générale, trop polyvalente. Il faut donc que des IA spécifiques aux différents domaines se développent, mais pour développer de telles IA il faut un nombre conséquent de données liées à ces domaines. Or, ces données sont possédées par les entreprises du secteur concerné dont les propriétaires n’ont aucun intérêt à les partager pour entrainer des IA qui pourraient être utilisées par leurs concurrents, ce qui restreint les capitalistes à entrainer des IA sur leurs seules données propres.
Au-delà des affichages, et en plus des considérations éthiques, de fortes réticences existent toutefois au sein des cercles de défense européens sur la façon de monter en puissance avec l’IA. Pour être performants, les algorithmes nécessitent la mise en commun de données hétérogènes, certaines classifiées, notamment tirées des « opérations » militaires mais aussi civiles. De nouveaux entrants comme Mistral AI ou la société d’IA franco-allemande Helsing – toutes fondées ou dirigées par des anciens de Google, de Meta ou de Palantir -, essaient ainsi d’insérer dans l’écosystème. Mais les industriels comme Thales ou Dassault, qui font eux-mêmes de l’IA, ne sont pas prets à partager sans garde-fou leurs savoirs… (Le Monde, 11 février 2025)
Ce besoin de données ouvertes et accessibles est entravé par la propriété privée et intellectuelle. Le capitalisme est un frein au développement technologique et donc à celui des forces productives.
Baisse tendancielle du taux de profit et du stock de données
Il y a certes un travail humain initial dans la conception, l’installation des infrastructures, la préparation des jeux de données et ensuite une partie de maintenance mais la réserve de plus-value est en réalité très faible dans le secteur du « deep learning ». Dans le cas d’usage massif de l’IA dans les branches productives, les groupes capitalistes de l’informatiques capables de fournir de tels services capteraient dans les faits une partie de la plus-value de ces secteurs.
Les entreprises consommatrices de ces IA, accepteraient de céder une partie de leur plus-value dans l’optique d’abaisser la main-d’œuvre nécessaire. En conséquence d’autres entreprises seraient incapables de répondre à celles employant moins de salariés au profit d’un abonnement IA. Dans chacune des deux situations, des emplois salariés seraient amenés à disparaitre. D’une part, s’en suivrait une baisse de la plus-value disponible totale dans ces secteurs. Et d’autre part, puisque pour être performantes malgré les évolutions d’un secteur, ces IA ont constamment besoin de nouvelles données, la baisse de travail humain va en parallèle conduire à la baisse de nouvelles données disponibles. En d’autres termes, l’usage massif de l’IA dans les entreprises tendra à amoindrir les possibilités d’adaptation aux évolutions des méthodes de production.
Le cas se produit déjà dans le secteur de la programmation informatique. Depuis longtemps, les développeurs confrontés à un problème ou une question interrogent leurs pairs sur des plateformes d’entraides informatiques et autres forums dédiés sur Internet. Ces questions et ces réponses constituent une part importante des données d’entrainement des IA génératives de code (dont la plus connue est Github Copilot de Microsoft), mais le déploiement de ces IA dans les entreprises fait que les développeurs, en utilisant ces IA, ont moins besoin de passer par ces sites pour se débloquer, tarissant dès lors les nouvelles données d’apprentissage disponibles. Le site internet Stack Overflow est le plus connu et le plus utilisé des forums d’entraide de développeurs (20 millions d’utilisateurs enregistrés, 24 millions de questions et 36 millions de réponses), depuis l’apparition des IA conversationnelles d’abord (déjà capables de répondre à certaines questions de programmation) puis des IA spécifiques au code, ce site a vu sa fréquentation et le nombre de nouveaux sujets ouverts diminuer. Une baisse de 64 % des nouvelles questions et réponses entre avril 2024 et avril 2025.
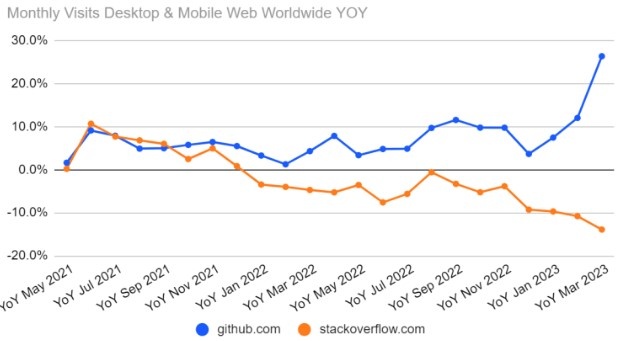
Des rapports de Similar Web font état d’une baisse de 14 % du nombre de visites sur le site web après la mise en place de ChatGPT en novembre. Cela peut s’expliquer en partie par une évolution connexe, l’introduction de l’assistant de codage CoPilot de l’entreprise GitHub de Microsoft. CoPilot est construit sur le même modèle de langage OpenAI que ChatGPT, capable de traiter à la fois le langage humain et le langage de programmation. Un plugin pour Microsoft Visual Studio Code, largement utilisé, permet aux développeurs de demander à CoPilot d’écrire des fonctions entières en leur nom, plutôt que d’aller sur Stack Overflow à la recherche de quelque chose à copier et coller. CoPilot intègre désormais la dernière version GPT-4 de la plateforme OpenAI. (Developpez.com, 13 mai 2023)
Même chose en ce qui concerne les données de la toile, la tendance actuelle à remplacer les moteurs de recherche dirigeant vers des sites par des IA répondant directement sans redirection de l’internaute va amplifier le phénomène de fermeture de site Web, phénomène déjà à l’œuvre depuis l’avènement des plateformes fermées telles que les réseaux sociaux (Facebook, Instagram, TikTok…). Les entreprises de l’information, face à la concurrence et à l’utilisation de leurs données par l’IA, protègent de plus en plus leurs contenus derrière des portails payants (paywall) rendant inaccessibles ceux-ci au IA. Ces deux facteurs vont contribuer à tarir internet, jusqu’ici principal abreuvoir des IA génératives. Autrement dit, l’utilisation d’un outil (l’IA) diminue la ressource nécessaire à la production de cet outil.
Pour qu’une IA soit pertinente, il faut que les données soient raisonnablement validées. En amenuisant le travail salarié dans les secteurs où l’IA serait déployée en masse, ces annotations vont mécaniquement se raréfier et dans l’extrême il ne restera que les données liées à l’activité de l’IA pour entrainer les nouveaux modèles.
Un remodelage de l’emploi
Bien que ces technologies n’aient pas pour le moment justifié les investissements faramineux qui leur sont attribués, les capitalistes impatients de faire plus avec moins entament déjà les plans de licenciements.
La bascule opérée dans l’intelligence artificielle il y a une dizaine d’années permet à ces modèles de rattraper et même dépasser l’être humain dans plusieurs domaines et offre ainsi la possibilité de faire traiter par des machines des tâches qui jusqu’alors avaient échappé à la mécanisation, la robotique et l’informatique formelle.
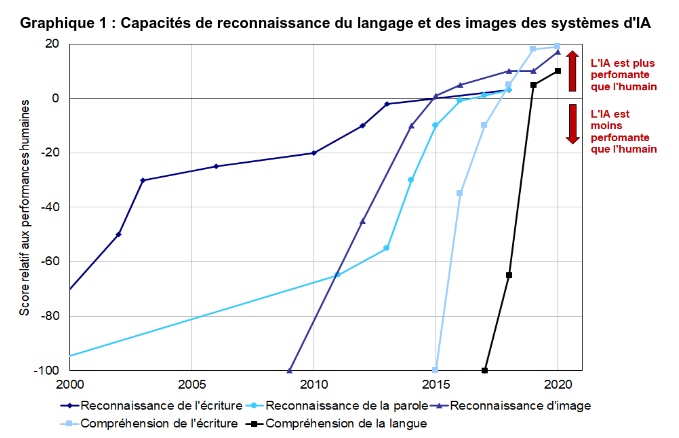
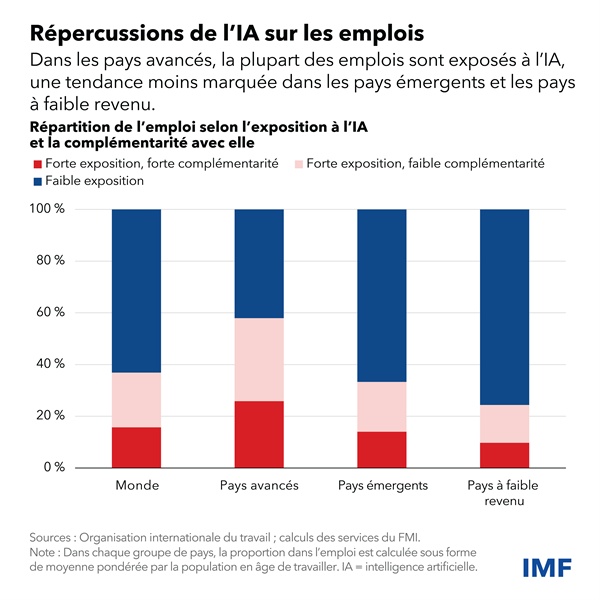
Par ailleurs, les premières estimations empiriques s’accordent sur le fait que les tâches et métiers touchés par l’IA ne seraient pas les mêmes que ceux qui étaient concernés par les précédentes révolutions technologiques. L’IA concernerait davantage les professions qualifiées, du fait de sa capacité à prendre en charge des tâches abstraites et non-routinières, alors que les vagues précédentes de mécanisation et d’informatisation avaient respectivement concerné les emplois non qualifiés et les professions intermédiaires. (Direction générale du Trésor, avril 2024)
Si les IA actuelles peuvent prédire la structure tridimensionnelle des protéines (AlphaFold), décrypter le langage des dauphins (DolphinGemma) ou même lire des rouleaux de parchemin antiques carbonisés, ce sont bien leurs capacités réelles ou supposées à remplacer le travail humain générateur de profit qui attise la voracité des capitalistes.
Le paradigme intellectuel dominant dans le secteur des technologies numériques d’aujourd’hui favorise aussi la voie de l’automatisation. L’un des principaux objectifs de la recherche en IA est d’égaler l’humain dans une vaste gamme de tâches cognitives et, plus généralement, de parvenir à une intelligence générale (artificielle) qui imite et surpasse les capacités humaines. Cette orientation intellectuelle encourage les technologies d’automatisation plutôt que les technologies de complémentarité avec l’humain. (FMI, Finances & développement, décembre 2023)
Le 14 janvier le Conseil économique social et environnemental tablait sur un fort impact sur les emplois administratifs, de la comptabilité et de l’assurance. D’autres domaines pourraient être également touchés, comme les ressources humaines, le marketing, le journalisme, le juridique, la traduction, la vente en ligne… Les femmes qui sont majoritaires dans ces secteurs seraient les plus impactées tout comme les jeunes diplômés à qui l’on confie des besognes de novices souvent répétitives. Le 20 mai dernier, une étude conjointe de l’Organisation internationale du Travail (OIT) et de l’Institut national de recherche de Pologne (NASK) estime que dans les pays à revenu élevé, 9,6 % de l’emploi des femmes est menacé par l’IA générative contre 3,5 % de l’emploi des hommes. La typologie d’emplois touchés induit également une différence d’impact entre les économies impérialistes et les pays dominés.
Des tâches variées sont ainsi confiées à des IA comme :
- la reconnaissance vocale permettant la saisie de notes, de compte-rendu de réunion, de commande dans un logiciel de vente,
- la reconnaissance d’image permettant de piloter la gestion de stock ou le contrôle de la production (Toyota…),
- la génération prédictive de texte dans la saisie des mails ou autres documents
- la recommandation personnalisée de produit (Amazon, Netflix, Starbucks…),
- le service client automatisé par des chatbots (Orange…),
- l’analyse automatique de CV de candidats (Linkedin…),
- les prévisions de commande facilitant la gestion de stock (Amazon, Starbucks, Walmart…),
- l’optimisation des itinéraires de livraison (DHL, UPS…),
- la maintenance prédictive (Airbus, General Electric, Siemens…),
- la détection de fraude (JPMorgan Chase, Paypal…),
- l’analyse et l’optimisation énergétique (Alphabet/Google…),
- le ciblage publicitaire…
Si le capitalisme s’intéresse au remplacement du travail humain par des IA dans ses entreprises, il compte aussi baisser le cout inhérent à l’État par le même biais. De nombreuses agences gouvernementales américaines ont signé un contrat avec OpenAi. Le gouvernement fédéral comme le gouvernement britannique a conclu un accord avec Microsoft pour des solutions IA.
Pour ce qui est de la France, Stanislas Guerini lançait en mai 2023 une expérimentation conjointe à la CAF, l’Assurance maladie et la CNAV développée par la startup américaine Anthropic AI. Gabriel Attal alors premier ministre présentait en avril 2024 Albert, une solution d’IA développée au sein de la direction interministérielle du numérique. Cet outil dont le déploiement est toujours en cours vise à automatiser une partie des tâches des différentes administrations.
Aussi Albert accompagnera-t-il les agents de l’administration fiscale pour rédiger des préréponses aux 16 millions de messages envoyés chaque année par les usagers dépassés. Mais ce n’est pas tout. Albert permettra aussi aux directions régionales de l’environnement de pré-instruire les dossiers d’aménagement urbain, aux greffiers d’automatiser la retranscription d’audiences judiciaires, aux policiers d’automatiser le dépôt de plaintes… (Le Point, 25 avril 2024)
En février 2025, France travail signait avec la startup française Mistral AI pour la création de ChatFT (Chat France travail) un assistant pour les conseillers et MatchFT qui présélectionne automatiquement pour chaque offre d’emploi des candidats en fonction de leurs CV et leur envoie un SMS de contact.
Meta a démarré en février dernier l’allègement de 5 % de ses effectifs (3 600 salariés) au profit de l’IA, le 13 mai Microsoft lui répond en annonçant la suppression de 3 % de sa masse salariale (6000 personnes). Mais certaines entreprises vont bien plus loin. Début 2024, Duolingo, une entreprise américaine proposant un site internet et une application d’enseignement des langues, se sépare de 10 % de ses salariés au profit de l’IA, visant en priorité ceux résidant dans des économies avancées. Le 28 avril dernier, son PDG annonce que les prestataires et les travailleurs indépendants seront à leur tour remplacé par de l’IA. En France, Onclusive basée à Courbevoie et spécialisé dans les revues de presse à destination des entreprises annonce son intention de remplacer l’essentiel de ses salariés (217) par une IA en engageant un plan social au motif de « Mutation technologique ». En Inde, Dukaan une entreprise de commerce en ligne licencie 90 % de son effectif à l’été 2023, remplacé par un robot conversationnel à base d’IA.
La résistance du prolétariat
Évidemment, les grèves sont monnaie courante dans ce contexte. Le 2 mai 2023, aux États-Unis, le WGA (syndicat des écrivains américains), démarre une grève des scénaristes, celle-ci se termine le 23 septembre par un accord avec l’AMPTP (Alliance des producteurs de cinéma et de télévision) apportant des garanties sur l’utilisation de l’IA. Le 14 juillet de la même année, le SAG-Aftra (Syndicat des acteurs – fédération américaine des artistes de la télévision et de la radio) organise la grève des 160 000 acteurs, danseurs et cascadeurs de films et séries là encore pour obtenir des garde-fous sur l’emploi de l’IA dans le secteur, un accord est trouvé le 9 novembre. Le 26 juillet 2024, le même syndicat appelle cette fois-ci les 2 600 comédiens du jeu vidéo à la grève. Ces travailleurs réalisant le doublage et la capture de mouvement des personnages, ont depuis signé quelques accords ponctuels mais sont toujours en lutte contre les capitalistes du secteur (Activision, Disney, Electronic Arts, Insomniac Games, Take 2…). Les salariés de ces secteurs craignent que leur travail ne serve à entrainer des IA capables à terme de les remplacer. De l’autre côté de l’Atlantique, en Belgique, les salariés du groupe hospitalier Helora se sont mis en grève le 27 janvier 2025 après l’annonce par la direction de la suppression de 60 postes de secrétaires médicales au profit d’une solution d’IA. En France, les bureaux de Poste d’Evreux étaient fermés le 22 janvier 2024, en réaction à l’introduction de l’outil POP IA pour la gestion du planning des agents. Même chose à Météo France qui connait depuis 2023 des grèves régulières sur les baisses d’effectif et l’utilisation de l’IA avec des résultats pour le moins hasardeux.
Le problème, c’est que depuis quelque temps, les couacs se sont succédé au sein de l’établissement public. En plein mois de décembre, le bulletin météo annonçait 28 degrés à Strasbourg. Les inquiétudes montent au sein des agents qui s’interrogent sur la fiabilité du système. (RFI, 10 mars 2024)
De tels outils détenus par les capitalistes ne peuvent que servir leur rapacité au détriment du plus grand nombre. Comme à chaque palier technologique modifiant les forces productives, l’amélioration des conditions de vie des travailleurs ne passera pas par le rejet de l’IA mais bien par son expropriation des mains de la bourgeoisie.
Il faut du temps et de l’expérience avant que les ouvriers, ayant appris à distinguer entre la machine et son emploi capitaliste, dirigent leurs attaques non contre le moyen matériel de production, mais contre son mode social d’exploitation. (Karl Marx, Le Capital, I, Éditions sociales, t. 2, p. 110)